
There is widespread frustration with the quality of reviews for the major machine learning conferences as easily documented on twitter a few hours after reviews are released by NeurIPS, ICLR, ICML, etc. And of course, there will always be some poor decisions when many 1000s of papers are submitted to each conference each year (over 9000 papers were submitted to NeurIPS in 2021). More concerning are various analyses of the review process suggesting decisions are extremely noisy. But even more problematic, most reviewers and editors have a profound misunderstanding regarding the importance of falsification in science, and consequently, they systematically use the wrong criterion when evaluating research that is challenging existing work.
This blogpost is inspired by a recent rejection from ICML, but it could just as well be inspired by several of our rejected papers from NeurIPS or ICLR as well as some high-profile journals where editors often suffer the same confusion regarding falsification. A common feature of these papers is that they highlighted the limitations of specific models and undermined key conclusions that were drawn from their initial successes. What we find so problematic with our collection of rejections is that the editors do not dispute our findings but note that we have not “solved” the problem we have identified. It is standardly noted that we have only shown a small set of models have failed in some way, and that it is possible that some other model might succeed.
But this is misunderstanding the central role of falsification in science.
Yes, of course, some other models might succeed, and indeed, some sort of neural network must succeed (the human brain for example). But this does not minimize the importance of highlighting failures of existing models that have been used (mistakenly) to make important claims regarding the computational capacities of network architectures or make claims about the close links between networks and brains. But in the world of machine learning, the important thing is to build things — identifying limitations of existing published research, not so much.
This view is widespread. A nice example comes from researchers dismissing critiques of Gary Marcus. For example:
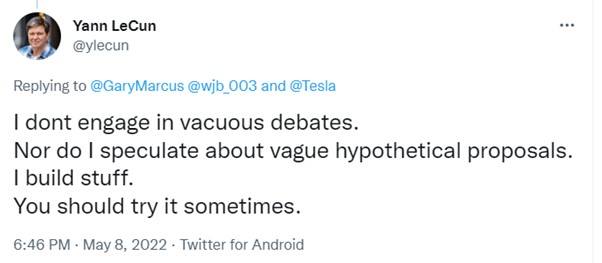
Similarly, this commitment to building stuff and not worrying about “philosophy” is nicely captured in a recent twitter Thread by Nando de Freitas that includes:

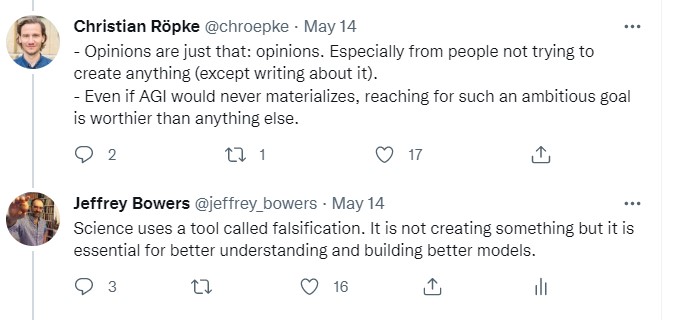
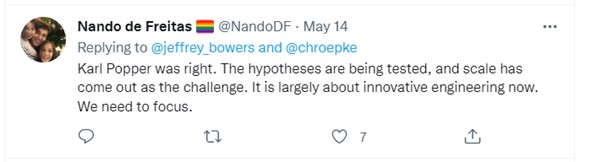
I do wonder whether Popper today would agree that it is all about engineering now, or whether “I build stuff” arguments would cut ice with him.
In the case of our ICML paper, the editor writes: “The authors investigate the challenging problem of combinatorial generalization in disentangled generative models and study when this generalization succeeds and when it fails… In large parts the paper reproduces existing results and failure modes (with modifications) but does not propose a method to overcome those — while this is not necessary for acceptance a more thorough investigation is necessary for an empirical paper”, and a critical reviewer writes: “I read the author response, and I appreciate the authors’ comments and additional experiments. But, they does not provide methods or suggestions to overcome their proposed problem. So, I will keep my recommendation.”
We get similar responses all the time. From ICLR: “This paper would have been a stronger paper if authors had suggested mechanisms or solutions which could have reduced dataset bias or geared CNNs towards extracting shape like features”; from NeuIPS: “The main conclusion in this paper is that humans have different learning mechanisms for visual object recognition than CNNs. It does not suggest a model for object recognition that is closer to human behavior or points to a fundamental failure mode in CNNs as typical NeurIPS papers often do”; from PLOS Computational Biology: “For this paper to substantially improve our understanding, the authors should offer a computational model that would simulate and explain the human behavior in this task, at least to a certain extent.” The list goes on. I think it is fair to say that *all* of our papers that highlight some limitations of previous findings are criticized in a similar way. Occasionally we succeed in arguing our case, but most often, these criticisms are considered decisive.
This focus on providing solutions and ignoring or downplaying falsifications is reminiscent of a similar bias in psychology where it is much easier to publish positive than negative results. This has contributed to a mischaracterization of findings and a replication crisis that has attracted so much attention as of late in psychology. The equivalent here is the strong preference to publish successes rather than failures of neural networks. In fact, both null results and failures provide important constraints for theory and directions for building stuff, but these studies rarely see the light of day. In our view this has led to serious mischaracterizations of the successes of deep networks as models of the human mind as detailed in this twitter thread with links to (our often unpublished) work: https://twitter.com/jeffrey_bowers/status/1516790106555916288/
Of course, not all failures are important. For falsifications to merit publication the work must be addressing important claims and the falsification must be compelling in the sense that it undermines the conclusions that were drawn from published work. But what should not be required is to falsify an entire class of models, including yet to be invented models. It should be sufficient to falsify the conclusions that were drawn from existing work. But as the field currently stands, many papers are being published with claims of dramatic successes with little attempt to falsify the claims. It is not clear how many of these claims will stand up to scrutiny – in our experience, not often. But you are unlikely to hear about these failures in top conference proceedings or journals.