
Go to | Basic Research
Go to | Applied Research
Generalisation in Mind and Machine
Can we use Deep Neural Networks to understand how the mind works? The 5-year ERC grant entitled “Generalisation in Mind and Machine” compares how humans and artificial neural networks generalise across a range of domains, including visual perception, memory, language, reasoning, and game playing.
Why focus on generalisation? Generalisation provides a critical test-bed for contrasting two fundamentally different theories of mind, namely, symbolic and non-symbolic theories of mind. Symbolic representations are compositional (e.g., Fodor and Pylyshyn, 1988) and are claimed to be necessary to generalise “outside the training space” (Marcus,1998, 2017). By contrast, non-symbolic models, including PDP models and most Deep Neural Networks reject the claim that symbolic representations are required to support human-like intelligence. So can non-symbolic neural networks generalise as broadly as humans? If so, this would seriously challenge a core motivation for symbolic theories of mind and brain. You can find out more about our research on this topic here.
Are there grandmother cells?
Grandmother cells refer to the hypothesis that single neurons codes for specific familiar categories, such as grandmothers. On this view, you should be able to find neurons that respond most strongly to one known word, object, or face. This hypothesis is typically dismissed out of hand, and indeed, the term itself is pejorative – it seems absurd to claim that a single neuron codes for your grandmother of all people. The claim that grandmother cells are biological implausible is one of the key arguments put forward in support of Parallel Distributed Processing (PDP) and against “localist” theories in psychology.
Nevertheless, my colleagues and I (along with a handful of others; e.g., Mike Page, Simon Thorpe, John Hummel, Gabriel Kreiman, Maximillian Riesnhuber, Stephen Grossberg) have argued that grandmother cells are biologically plausible when property define (Preface). Not only is the neuroscience consistent with grandmother cells (Bowers, 2009), we have shown that PDP models learn grandmother cells when trained to code for multiple items at the same time in short-term memory (Bowers et al., 2014, 2016).

Image of a single hidden unit that responds to the letter ‘k’. Activation of the unit is coded along the x-axis, and words are presented in alphabetical order along the y-axis. All words that contain the letter K are highly active, and all other words have a low activation.
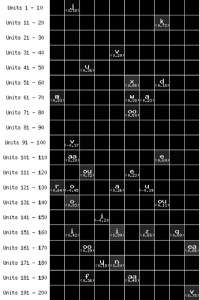
The k-unit was not an outlier. In this figure (on the right), the selective units are labelled with the letter they respond to, with the number indicating the degree of selectivity (as defined in the paper). As you can see, there are grandmother cells for many letter units. In some cases, lesioning a single hidden unit (out of 200) lead the model to selective fail in recalling words that contained that letter. Taken from Bowers et al., (2016).

Left figure: A unit responds selectively to the trained word ‘gus’ rather than a letter (taken from Bowers et al., 2014).
In some conditions recurrent networks include hidden units that learned to selectively respond to words rather than letters. Importantly, the networks in the above two papers only learned selective units when trained to code for multiple words at the same time in short-term memory. We argued that the local codes provide a solution to the so-called ‘superposition catastrophe’. This is the claim that overlapping distributed patterns are ambiguous as you cannot unambiguously recover the patterns that contributed to the blend (there are many different possible combinations of patterns that can produce a given blend). Just as Marr argued that non-overlapping representations are required in the hippocampus in order to learn quickly without erasing old memories (solving the so-called stability-plasticity dilemma, or catastrophic interference), we argue that the cortex learns selective (non-overlapping) representations to overcome the superposition catastrophe.
Interestingly, so-called ‘deep networks’ that are the taking over artificial intelligence sometimes learn grandmother units even when items (e.g., photos of faces) are processed one-at-a-time (for reviews see: Bowers, 2017ab). This suggests that there are additional functional pressures to learn highly selective (perhaps grandmother cell) representations in the visual system (in cortex) above and beyond the superposition catastrophe. This work has been and is currently funded by the Leverhulme Trust.
Bowers, J.S. & Davis, C. J. & (2016-2019). When and why do neural networks learn selective codes? The Leverhulme Trust. ~250K
Bowers, J.S. (2011-2013). The Role of Local and Symbolic Representations in Mind and Brain. Leverhulme Trust, ~£200K
Is the Mind/Brain a Symbolic or Non-symbolic Device?
Theories of perception and cognition can be divided into two general approaches: The “symbolic” approach associated with Turing, Chomsky, Fodor, and Pinker, amongst others, and the “non-symbolic” approach associated with Skinner, Rumelhart, McClelland, Hinton, amongst others.
A key claim of symbolic models is that certain forms of generalization (roughly extrapolation rather than interpolation) require componential representations in which new complex representations are composed of familiar parts that retain their identity in different contexts. Non-symbolic models deny the claim that representations are compositional in this sense.
I have provided empirical and computational arguments in support of the symbolic approach. In one line of research my colleagues and I have shown that humans generalize in the domains of vision (Bowers, Vankov, & Casimir, 2015), written word identification (Davis & Bowers, 2006; Bowers, Davis, & Hanley, 2005), and spoken word identification (Bowers, Kazanina, Andermane, 2016; Kazanina, Bowers, & Idsardi, 2017) in ways that pose a challenge for non-symbolic theories. In another line of research, we have highlighted the limited generalization capacities of non-symbolic networks (Bowers et al., 2009; Bowers, & Davis, 2009). I am currently interested in the issue of how to build biologically plausible symbolic networks. Here is a highly speculative paper where I outline the possible role of myelin plasticity in developing biologically plausible symbolic models (Bowers & Davis, 2017). The following Opinion article in TICS outlines why localist and symbolic theories of mind and brain should be taken seriously (Bowers, 2017). This work is currently being supported by an ERC grant. Bowers, J.S. (2017-2022). Generalisation in Mind and Machine. ERC advanced Grant, ~2.5 million euros.
Is the Brain Bayesian?
I have argued that Bayesian theories of mind and brain are largely post-hoc and that the theoretical claims are often unclear (Bowers & Davis, 2012a,b). Here is a nice write-up of a workshop where Josh Tenenbaum and I took opposing views on the Bayesian Brain. I quite like the author’s conclusion that I won the debate! https://blogs.scientificamerican.com/cross-check/are-brains-bayesian/
The importance of Early Word Learning
I have a long-standing interest in word learning, and have addressed various question. Age-or-acquistion effects and Forgotten Language. Here I summarise two:
1] Age-of-acquisition effects: One important factor in determining how fast you can read a word is how often you have read it – the so-called word frequency effect. Another more controversial claim is that the age at which you learn a word impacts on learning as well – the so-called age-of-acquisition effect. A key challenge is that most early acquired words are also high-frequency, so it difficult to disentangle the two effects. In order to overcome this problem, we assessed how quickly academic psychologists, chemists, and geologists read technical words in their area of expertise (e.g., how quickly does a chemist read the word ‘carbon’). For experts, the technical words can be orders of magnitude more frequent than some early-acquired such as ‘dragon’. Nevertheless, we found that the experts read the technical words equally quickly, highlighting the importance of age-of-acquisition in learning.
Stadthagen-Gonzalez, H., Bowers, J.S., & Damian, M.F. (2004) Age of Acquisition Effects in Visual Word Recognition: Evidence From Expert Vocabularies. Cognition, 93, B11-B26.
2] Forgotten Language? We followed-up an interesting study by Pallier et al. (2003) who assessed the language skills of children who were fluent in Korean as children before being adopted by French parents. Strikingly, they completely forgot their Korean when tested as adults. We obtained the same results in children who learned Hindi in Delhi and Zulu in South Africa as children but then moved to the UK. However, we found that about half our participants could be retrained to hear speech sounds from these languages that others cannot. This shows that early language knowledge was not entirely lost when probed with more sensitive measures.
Bowers, J.S., Mattys, S.L., & Gage, S.H. (2009). Preserved implicit knowledge of a forgotten childhood language. Psychological Science, 20, 1064-1069.
Implicit Memory
For much of my early career I focused on an unconscious or implicit form of memory called priming. Priming is revealed when you are faster or more accurate identifying a word or picture when it is repeated a few minutes later. This attracted a lot of attention given that even amnesic patients show priming even though they cannot remember previously seeing the word or object a few minutes before. This posed a serious challenge for many theories of memory. I argued that priming is best conceptualized as a form of perceptual learning, with visual word priming reflecting word learning within the visual word recognition system (so-called orthographic system) and object priming reflecting learning within the visual object recognition system. This was a different perspective than most memory researchers adopted, and led to an edited book on this topic **.

Miscellaneous
Swearing? Perhaps the paper that my student like best is one that considers why we have such strong emotional reaction to taboo words (I will not write them down), but not to euphemisms of those words (e.g., F-word, C-word). In this paper we report stronger galvanic skin responses to taboo compared to euphemisms, and detail an argument about how this is relevant to the topic of linguistic relativity. This paper was probably rejected by over a dozen journals, and I gave up on it for years until the journal PLoS ONE came along that only evaluates papers on the method and not the theory. I quite like the idea though.
Bowers J.S., & Pleydell-Pearce C.W. (2011). Swearing, Euphemisms, and Linguistic Relativity. PLoS ONE 6(7): e22341.doi:10.1371/journal.pone.0022341
 Psychology and Politics: A feature of some recent televised election debates has been the introduction of ‘‘the worm’’ that represents the average response of a small sample of undecided voters who watch the debate and record their satisfaction with what the leaders are saying (see figure on the right for an example worm). We reported an experiment with 150 participants in which we manipulated the worm and superimposed it on a live broadcast of a UK election debate. The majority of viewers were unaware that the worm had been manipulated, and yet we were able to influence their perception of who won the debate, their choice of preferred prime minister, and their voting intentions. This is a serious problem given that the worm is typically generated by a very small sample of voters, and indeed, there have been reports that the worm is sometimes biased.
Psychology and Politics: A feature of some recent televised election debates has been the introduction of ‘‘the worm’’ that represents the average response of a small sample of undecided voters who watch the debate and record their satisfaction with what the leaders are saying (see figure on the right for an example worm). We reported an experiment with 150 participants in which we manipulated the worm and superimposed it on a live broadcast of a UK election debate. The majority of viewers were unaware that the worm had been manipulated, and yet we were able to influence their perception of who won the debate, their choice of preferred prime minister, and their voting intentions. This is a serious problem given that the worm is typically generated by a very small sample of voters, and indeed, there have been reports that the worm is sometimes biased.
Davis, C.J., Bowers, J.S., & Memon, A. (2011). Social Influence in Televised Election Debates: A Potental Distorion of Democarcy PLoS ONE, 6(3): e18154.